IXChat Package¶
LangGraph-based chatbot with retrieval-augmented generation (RAG), conversation memory, and intelligent visitor enrichment.
Overview¶
The ixchat package provides the core chatbot functionality for the Rose platform. It uses LangGraph to orchestrate a complex workflow of specialized nodes that handle:
- Document Retrieval: Fetches relevant context from LightRAG
- Visitor Enrichment: Identifies companies from IP addresses
- Response Generation: Produces contextual answers with LLM
- Skill-Based Personalization: Applies response ending skills based on visitor signals
- Suggestion Generation: Creates follow-up questions or answer options
- Dialog Supervision: Tracks conversation state and signals
Architecture Diagram¶
The following diagram shows the LangGraph structure. It is auto-generated from the graph definition using Graphviz during just build or just dev.
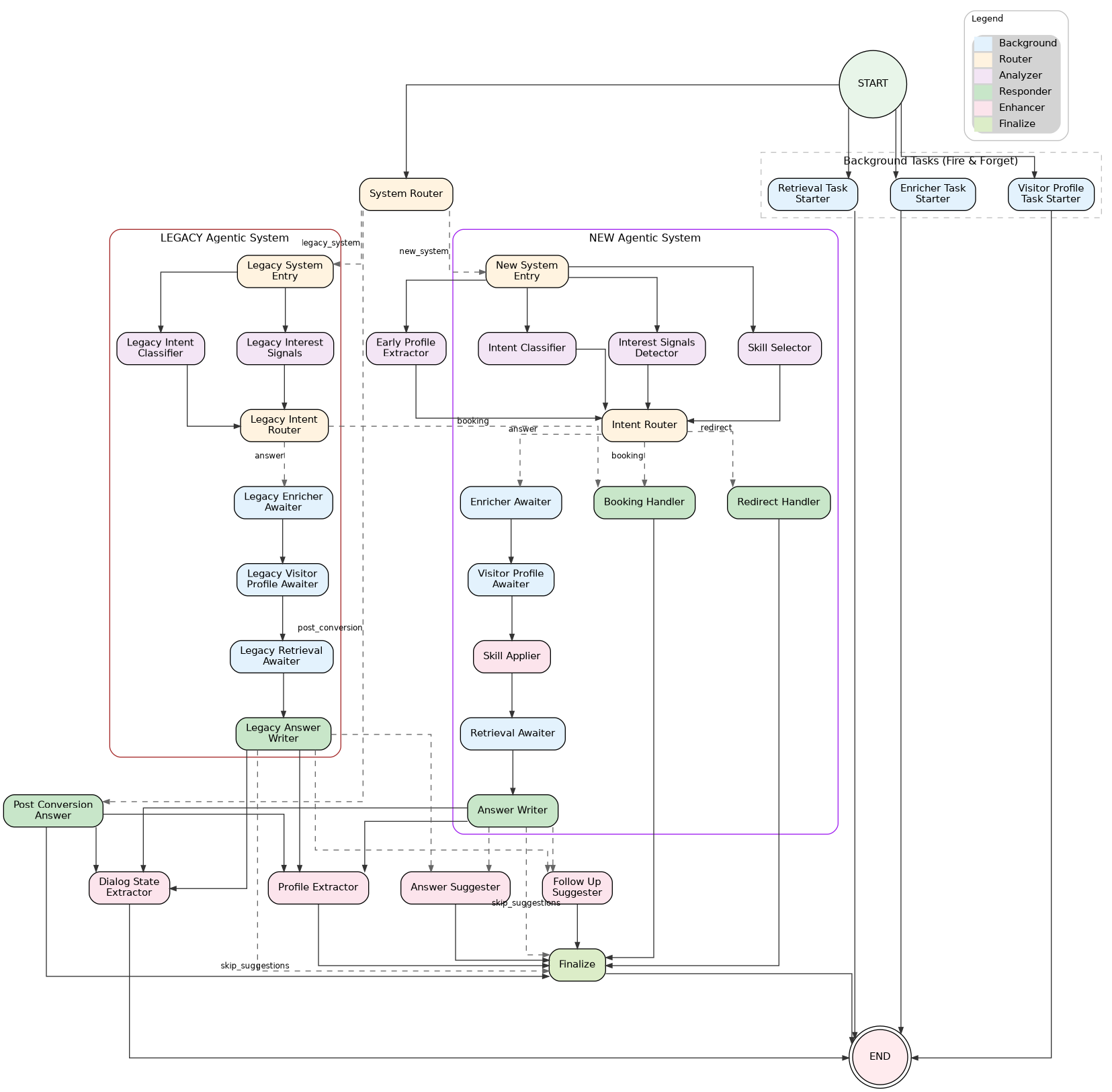
Agentic System Architecture¶
The graph runs a single agentic path from the system_router entry point, with a dedicated POST_CONVERSION branch for post-booking qualification. The standard path features the skills pipeline and 3-way routing (ANSWER/REDIRECT/BOOKING).
Multi-Agent Router Architecture¶
Overview¶
The multi-agent router architecture replaces the monolithic prompt approach with specialized agents for different visitor intents. Instead of one large prompt handling all scenarios, the system:
- Classifies intent using a fast LLM (gpt-4.1-nano)
- Selects response skills based on intent + interest signals
- Routes to specialized handlers based on intent (ANSWER/REDIRECT/BOOKING)
- Uses 3-level prompt hierarchy for each agent (meta-template → agent template → client instructions)
Intent Classification¶
The intent_classifier node classifies each message into one of 5 visitor intents:
| Intent | Description | Example |
|---|---|---|
LEARN |
Product questions, feature inquiries | "How does your A/B testing work?" |
CONTEXT |
User sharing business context | "We have 50k monthly visitors" |
SUPPORT |
Existing customer issues | "I can't log into my dashboard" |
OFFTOPIC |
Unrelated to product | "What's the weather today?" |
OTHER |
Job inquiries, press, partnerships | "Are you hiring?" |
The classifier runs in parallel with other analysis nodes after system routing, using the Langfuse prompt rose-internal-intent-router.
Skill Selection¶
The skill_selector node (LLM) selects response ending skills based on visitor intent, interest signals, and conversation history. Skills determine how the response should end (e.g., propose demo, collect email, suggest follow-up).
The skill_applier node (deterministic logic) then applies post-processing rules with current-turn signals:
- Demo forcing: Force demo skill when booking intent detected
- CTA timing: Control when to show CTAs based on turn count
- Signal overrides: Apply current-turn interest signals to skill selection
Intent Routing¶
The intent_router node uses deterministic logic (no LLM) to decide the next path based on:
- Current visitor intent
- Cumulative interest score (from
interest_signals_detector) - Site-specific interest threshold (from unified
qualification.interest_signals.threshold) - Skill selection results
| Path | Trigger | Handler |
|---|---|---|
ANSWER |
LEARN/CONTEXT intent, product questions (including PAUSE mid-booking) | answer_writer |
REDIRECT |
SUPPORT/OFFTOPIC/OTHER/HACK intent (including EXIT mid-booking) | redirect_handler |
BOOKING |
Demo requested or active booking field answer (STAY branch) | booking_handler |
Redirect Handler¶
The redirect_handler handles support, off-topic, and other requests by redirecting users to appropriate resources.
3-Level Prompt Hierarchy:
rose-internal/response-agents/meta-template (Level 1 - shared)
└── {{lf_agent_instructions}} ← Agent template inserted
└── rose-internal/response-agents/redirect/template (Level 2)
└── {{lf_client_agent_instructions}} ← Client instructions inserted
└── rose-internal/response-agents/redirect/instructions/{domain} (Level 3)
Key features:
- Skips enrichment and retrieval: The redirect path bypasses
enricher_awaiter,visitor_profile_awaiter, andretrieval_awaiterfor ~300-500ms faster responses. - Uses gpt-4.1-nano: Optimized for fast, lightweight redirect responses.
Booking Handler¶
The booking_handler manages CTA and email collection flows when high buying signals are detected:
- Email collection: Prompts for email when user shows demo interest
- Lead capture webhook: Fires webhook with
capture_context="in_chat_booking"when email is first captured - PostHog tracking: Sends
rw_email_capturedevent withrw_capture_context="in_chat_booking" - CTA insertion: Adds appropriate call-to-action based on visitor profile
- Skips enrichment: Like redirect, bypasses background awaiters for faster response
Routing Paths¶
| ANSWER Path | REDIRECT Path | BOOKING Path |
|---|---|---|
answer_writer |
redirect_handler |
booking_handler |
Deferred Execution Pattern¶
The graph uses a deferred execution pattern for ALL background operations to minimize latency:
| Starter Node | Awaiter Node | Operation | Latency Savings |
|---|---|---|---|
retrieval_task_starter |
retrieval_awaiter |
RAG retrieval | ~200-400ms |
enricher_task_starter |
enricher_awaiter |
Visitor enrichment (IP lookup) | ~100-300ms |
visitor_profile_task_starter |
visitor_profile_awaiter |
Visitor profiling (LLM inference) | ~200-400ms |
How it works:
- START: All task starters fire async tasks immediately and return to END (no blocking!)
- Analysis: Analysis nodes (
intent_classifier,interest_signals_detector,skill_selector) run in parallel with background tasks - Routing:
intent_routerdecides path without waiting for background results - ANSWER path: Awaiters sequentially collect background task results before answer generation
- REDIRECT/BOOKING paths: Skip all awaiters, allowing background tasks to be cancelled (~300-500ms faster + cost savings)
This reduces latency by ~50-66% since analysis doesn't wait for slow I/O operations. Background tasks that aren't awaited can be cancelled, saving compute costs on redirect/booking paths.
Parallel Execution Architecture¶
Four nodes start in parallel from START (all return immediately):
START ──┬── retrieval_task_starter ────────→ END [fires async RAG task]
├── enricher_task_starter ─────────→ END [fires async enrichment]
├── visitor_profile_task_starter ──→ END [fires async profiling]
│
└── system_router ──→ agentic_system_entry
Agentic System (3 analysis nodes in parallel):
system_router ──→ agentic_system_entry ──┬── intent_classifier ────────────┐
├── interest_signals_detector ────┼──→ intent_router
└── skill_selector ───────────────┘ │
├── ANSWER: enricher → visitor_profile → skill_applier → retrieval → answer_writer
├── REDIRECT: redirect_handler → finalize
└── BOOKING: booking_handler → finalize
Key architecture insights:
- Background tasks fire at START and return immediately (no superstep blocking!)
- REDIRECT/BOOKING paths skip all awaiters for faster response
Streaming Architecture¶
The chatbot uses a two-phase streaming approach:
Phase 1: Token Streaming (response handler)¶
- Uses LangGraph's
astream_eventsAPI to captureon_chat_model_streamevents - Only streams from response handler nodes (
answer_writer,redirect_handler,booking_handler) - other nodes are filtered out to avoid streaming JSON - Tokens sent as Server-Sent Events:
{"type": "token", "content": "..."}
Phase 2: Completion Event (after finalize)¶
After streaming completes, the API layer:
- Waits for all graph nodes to complete (including background nodes)
- Fetches final state:
chatbot.graph.aget_state(config_dict) - Extracts from state:
suggested_follow_ups- Follow-up questions fromfollow_up_suggestersuggested_answers- Answer options fromanswer_suggestercta_url_overrides- Dynamic CTA URLs fromform_field_extractorvisitor_profile- Enriched company dataskill_selection_state- Selected skills and metadata
- Sends completion event:
{"type": "complete", "metadata": {...}}
Why This Design?¶
- Fast time-to-first-token: User sees response immediately from the response handler
- Guaranteed enrichment: Awaiter nodes ensure background data is ready before answer generation
- Cancelled when unused: REDIRECT/BOOKING paths skip awaiters, allowing background tasks to be cancelled
- Complete data at end: Suggestions and metadata require all nodes to finish
Code Flow¶
# chatbot.py - Streams only response handler tokens
STREAMING_NODES = ("answer_writer", "redirect_handler", "booking_handler")
async for event in self.graph.astream_events(...):
if event_type == "on_chat_model_stream":
node_name = metadata.get("langgraph_node", "")
if node_name not in STREAMING_NODES: # Skip other nodes (analysis, etc.)
continue
yield chunk.content # Stream token to client
# chat.py (API) - Fetches final state after streaming
state = await chatbot.graph.aget_state(config_dict)
suggested_follow_ups = state.values.get("suggested_follow_ups", [])
suggested_answers = state.values.get("suggested_answers", [])
# ... send completion event with metadata
Execution Flow¶
-
START: Four nodes launch in parallel (all return immediately)
retrieval_task_starter- Fires retrieval task asynchronouslyenricher_task_starter- Fires enrichment task asynchronouslyvisitor_profile_task_starter- Fires profiling task asynchronouslysystem_router- Routes to the agentic system or post-conversion branch
-
System Entry:
agentic_system_entrybranches to 3 analysis nodes in parallelintent_classifier- Classifies visitor intent (LLM)interest_signals_detector- Detects buying signals (LLM)skill_selector- Selects response skills (LLM)
-
Intent Routing: All 3 analysis nodes converge at
intent_router- ANSWER intent →
enricher_awaiter(continue with enrichment) - REDIRECT intent →
redirect_handler(skip enrichment, faster) - BOOKING intent →
booking_handler(skip enrichment, faster)
- ANSWER intent →
-
ANSWER Path: Sequential processing with deferred results
enricher_awaiter- Awaits enrichment taskvisitor_profile_awaiter- Awaits profiling taskskill_applier- Applies post-processing rules with current-turn signalsretrieval_awaiter- Awaits RAG retrieval taskanswer_writer- Generates skill-based response
-
REDIRECT/BOOKING Paths: Fast response (skips all awaiters)
- Handler generates response →
finalize→ END
- Handler generates response →
-
Post-Processing: After answer generation
dialog_state_extractor- Extracts emoji markers and emails → ENDform_field_extractor- Extracts form field values →finalizesuggestion_router- Routes toanswer_suggester,follow_up_suggester, orfinalize
Graph Nodes¶
Background Task Nodes (Fire at START)¶
| Node | Purpose | Target |
|---|---|---|
retrieval_task_starter |
Fires RAG retrieval task asynchronously | retrieval_awaiter |
enricher_task_starter |
Fires visitor enrichment task asynchronously | enricher_awaiter |
visitor_profile_task_starter |
Fires visitor profiling task asynchronously | visitor_profile_awaiter |
System Routing Nodes¶
| Node | Purpose |
|---|---|
system_router |
Routes to the agentic system or post-conversion branch |
agentic_system_entry |
Entry point that branches to analysis nodes |
Analysis Nodes¶
| Node | Type | Purpose |
|---|---|---|
intent_classifier |
LLM | Classifies visitor intent (gpt-4.1-nano) |
interest_signals_detector |
LLM | Detects buying signals (engagement, pricing interest) |
skill_selector |
LLM | Selects response ending skills based on signals |
Routing & Processing Nodes¶
| Node | Type | Purpose |
|---|---|---|
intent_router |
Logic | Routes to ANSWER/REDIRECT/BOOKING based on intent + signals |
skill_applier |
Logic | Applies post-processing rules with current-turn signals |
enricher_awaiter |
Await | Awaits deferred enrichment task (ANSWER path) |
visitor_profile_awaiter |
Await | Awaits deferred profiling task (ANSWER path) |
retrieval_awaiter |
Await | Awaits deferred RAG retrieval task (ANSWER path) |
Response Handler Nodes¶
| Node | Purpose |
|---|---|
answer_writer |
Generates skill-based response with RAG context |
redirect_handler |
Handles support/offtopic/other redirects (gpt-4.1-nano) |
booking_handler |
Handles CTA/email collection flows |
Post-Processing Nodes¶
| Node | Type | Purpose |
|---|---|---|
dialog_state_extractor |
Async | Extracts emoji markers and captured emails |
form_field_extractor |
Async | Extracts form field values for CTA URLs |
follow_up_suggester |
LLM | Generates follow-up questions |
answer_suggester |
LLM | Generates suggested answers (when bot asks questions) |
finalize |
Sync | Assembles final response for client |
Abuse Protection & Rate Limiting¶
Two layers of protection prevent resource waste from spam, prompt injection, and duplicate requests. All checks run before the LangGraph graph is invoked, so blocked sessions consume zero LLM calls.
Layer 1: FastAPI Per-Session Concurrency Guard¶
The API layer (middleware/rate_limit.py) prevents parallel requests for the same sessionId:
- In-memory
set[str]+asyncio.Lock— no Redis needed (each Cloud Run instance handles its own sessions) - If a request is already in-flight for a session, the second request gets 429 immediately
- Session slot is released when the request completes (including streaming)
This prevents a misbehaving frontend or attacker from spamming the same session with concurrent requests.
Layer 2: Abuse Gate (Pre-Graph Checks)¶
The abuse gate (ixchat/utils/abuse_gate.py) runs in chatbot.py before graph.ainvoke() / graph.astream_events(). It checks three conditions:
| Check | Threshold | Behavior | Persistence |
|---|---|---|---|
| Hack count | hack_count >= 2 |
Permanent session block | Cumulative across turns, never resets |
| Spam count | spam_count >= 3 |
Temporary block | Resets to 0 when user sends a different message |
| Message length | > 15,000 chars |
Single message block | Per-message check |
Priority order: hack_count > spam_count > message_length.
Spam Detection Flow¶
Spam count is computed in chatbot.py._prepare_graph_inputs by comparing the current input to the previous turn's input (case-insensitive, whitespace-stripped):
Turn 1: "hello" → spam_count=0, last_input="hello" → allowed
Turn 2: "hello" → spam_count=1, last_input="hello" → allowed
Turn 3: "hello" → spam_count=2, last_input="hello" → allowed
Turn 4: "hello" → spam_count=3, last_input="hello" → BLOCKED
Turn 5: "different question" → spam_count=0 → UNBLOCKED
Both spam_count and last_input are persisted in RoseChatState and survive across turns via the LangGraph checkpointer (Redis).
Blocked Response Messages¶
- Hack block (permanent): Harsh tone — "I'm unable to continue this conversation. Please start a new session."
- Spam block (temporary): Softer tone — "It looks like you've sent the same message several times. Please try asking a different question."
Both responses are localized in 7 languages (en, fr, es, de, it, pt, nl).
State Fields¶
| Field | Type | Description |
|---|---|---|
hack_count |
int |
Cumulative HACK intents (2+ = permanent block) |
spam_count |
int |
Consecutive identical messages (3+ = temporary block) |
last_input |
str |
Previous turn's input text (for spam comparison) |
Key Files¶
| File | Role |
|---|---|
ixchat/utils/abuse_gate.py |
Check functions, thresholds, localized messages |
ixchat/chatbot.py |
Computes spam_count, calls abuse gate before graph |
ixchat/pydantic_models/state.py |
hack_count, spam_count, last_input state fields |
ixchat/nodes/intent_router.py |
Increments hack_count when HACK intent detected |
middleware/rate_limit.py |
Per-session concurrency guard (FastAPI) |
State Model¶
The graph uses RoseChatState (TypedDict) with custom reducers for parallel updates:
Core Fields¶
| Field | Type | Description |
|---|---|---|
messages |
list[BaseMessage] |
Conversation history |
input |
str |
Current user input |
response |
str |
Generated LLM response |
retrieved_docs |
str |
Context from LightRAG |
site_name |
str |
Client site identifier |
session_id |
str |
Conversation session ID |
turn_number |
int |
Current conversation turn (0-indexed) |
Profile & Signals¶
| Field | Type | Reducer |
|---|---|---|
visitor_profile |
VisitorProfile |
merge_visitor_profiles |
dialog_supervision_state |
DialogSupervisionState |
merge_dialog_supervision_states |
interest_signals_state |
InterestSignalsState |
merge_interest_signals_states |
form_collection_state |
FormCollectionState |
merge_form_collection_states |
Intent & Router State¶
| Field | Type | Description |
|---|---|---|
intent_classification_state |
IntentClassificationState |
Current intent + history |
intent_router_state |
IntentRouterState |
Next route + reasoning |
next_route |
str |
Pre-computed route for conditional edges |
VisitorIntent enum values: LEARN, CONTEXT, SUPPORT, OFFTOPIC, OTHER, BOOKING, STOP_BOOKING, HACK
NextAction enum values: EDUCATE, QUALIFY, PROPOSE_DEMO, HANDLE_BOOKING, HANDLE_STOP_BOOKING, HANDLE_SUPPORT, HANDLE_OFFTOPIC, HANDLE_OTHER, HANDLE_HACK, CONTINUE
Skill Selection State¶
| Field | Type | Description |
|---|---|---|
skill_selection_state |
SkillSelectionState |
Selected skills + metadata |
booking_state |
BookingState |
CTA/booking flow tracking |
Custom Reducers¶
Parallel nodes update state using custom merge functions:
merge_visitor_profiles: Merges enrichment results, preferring non-"unknown" valuesmerge_dialog_supervision_states: Cumulative "ever" flags + latest turn flagsmerge_interest_signals_states: Simple replacementmerge_form_collection_states: Merges collected values, tracks max turn
Memory Management¶
Session state is persisted using LangGraph checkpointers:
| Mode | Backend | Use Case |
|---|---|---|
| Redis | AsyncRedisSaver |
Production (distributed) |
| Memory | MemorySaver |
Development/Testing |
Configuration:
- TTL: Configurable session timeout
- Keepalive: TCP socket keepalive enabled
- Health checks: 30-second pings prevent idle disconnection
# Memory manager initialization
memory_manager = IXChatMemoryManager()
checkpointer = await memory_manager.get_checkpointer()
graph = graph_builder.compile(checkpointer=checkpointer)
Enrichment System¶
Multi-source visitor enrichment pipeline with priority-based fallbacks:
| Priority | Source | Description |
|---|---|---|
| 1 | Redis Cache | Fast, short-lived cache |
| 2 | Supabase Lookup | IP hash lookup for returning visitors |
| 3 | Browser Reveal | Client-side data (window.reveal) |
| 4 | Snitcher Radar | Session UUID identification |
| 5 | Enrich.so | Server-side API fallback |
Once a source returns "completed" status, remaining sources are skipped.
VisitorProfile Fields¶
- Enrichment:
status,tier,source,ip_address - Company:
company_name,company_description,company_domain,sector,sub_sector - User Context:
email,job_to_be_done,feature_list,intent - Confidence:
sector_confidence_level
Integration Points¶
| System | Purpose | Package |
|---|---|---|
| LightRAG | Document retrieval with graph & chunk ranking | ixrag |
| Supabase | Conversation storage, client configs, lead data | ixdata |
| LangFuse | Observability & tracing | ixllm |
| Azure OpenAI | LLM client | ixllm |
| Redis | Session checkpointing | ixchat.memory |
Key Files¶
| File | Description |
|---|---|
ixchat/__init__.py |
Public API: get_chatbot_service() |
ixchat/service.py |
IXChatbotService singleton manager |
ixchat/chatbot.py |
IXChatbot with LangGraph orchestration |
ixchat/graph_structure.py |
Graph structure (SINGLE SOURCE OF TRUTH for nodes/edges) |
ixchat/memory.py |
IXChatMemoryManager for session persistence |
ixchat/config.py |
Site configuration from Supabase |
ixchat/background_task_store.py |
Manages background tasks (retrieval, enrichment, profiling) |
ixchat/nodes/ |
Node implementations |
ixchat/nodes/intent_classifier.py |
Intent classification using LLM |
ixchat/nodes/intent_router.py |
Deterministic intent routing (ANSWER/REDIRECT/BOOKING) |
ixchat/nodes/skill_selector.py |
Skill selection using LLM |
ixchat/nodes/skill_applier.py |
Post-processing with current-turn rules |
ixchat/nodes/answer.py |
Skill-based answer generation |
ixchat/nodes/redirect_handler.py |
Redirect agent for support/offtopic/other |
ixchat/nodes/booking_handler.py |
CTA/email collection handler |
ixchat/nodes/retrieval_task_starter.py |
Fires retrieval task at START |
ixchat/nodes/retrieval_awaiter.py |
Awaits deferred retrieval task |
ixchat/nodes/enricher_task_starter.py |
Fires enrichment task at START |
ixchat/nodes/enricher_awaiter.py |
Awaits deferred enrichment task |
ixchat/nodes/visitor_profile_task_starter.py |
Fires profiling task at START |
ixchat/nodes/visitor_profile_awaiter.py |
Awaits deferred profiling task |
ixchat/pydantic_models/ |
State definitions and reducers |
ixchat/pydantic_models/state.py |
RoseChatState main graph state |
ixchat/pydantic_models/intent_router.py |
Intent router state models |
ixchat/pydantic_models/skill_selection_state.py |
Skill selection state |
ixchat/pydantic_models/booking_state.py |
Booking/CTA flow state |
ixchat/enrichment/ |
Multi-source visitor enrichment |
ixchat/enrichment/unified_enricher.py |
Orchestrates enrichment pipeline |
Usage¶
from ixchat import get_chatbot_service
# Get singleton service
service = get_chatbot_service()
# Get chatbot for a site
chatbot = await service.get_chatbot("example-site")
# Query with streaming
async for chunk in chatbot.query_stream(
input="Tell me about your product",
site_name="example-site",
session_id="session-123",
person_id="posthog-distinct-id",
):
print(chunk, end="")
# Non-streaming query (for evaluations)
response, metadata = await chatbot.query(
input="What are your pricing plans?",
site_name="example-site",
session_id="session-123",
)
Evaluations¶
The just eval command runs LLM evaluation tests for quality assessment and regression testing of ixchat components using Langfuse datasets.
How It Works¶
Langfuse Dataset ──→ Evaluator ──→ Classifier (LLM) ──→ Results logged to Langfuse
(labeled examples) (real API calls) (runs + scores)
- Test data is fetched from Langfuse datasets (labeled input/expected_output pairs)
- Evaluator runs the classifier on each dataset item
- Results are logged back to Langfuse as runs with scores (correct, confidence, F1, etc.)
- Metrics are computed (accuracy, F1, precision, recall) and asserted against thresholds
Usage¶
cd backend
# Run a specific evaluation
just eval intent-classifier # Intent classification accuracy
just eval skill-selector # Skill selection accuracy
just eval e2e-api # End-to-end API evaluation
# Run all evaluations
just eval all
Available Targets¶
| Target | Langfuse Dataset | Description |
|---|---|---|
intent-classifier |
intent-classifier |
Tests intent classification (LEARN, CONTEXT, SUPPORT, OFFTOPIC, OTHER) |
skill-selector |
skill-selector |
Tests skill/action routing decisions |
e2e-api |
main-dataset |
End-to-end API response quality |
Langfuse Dataset Structure¶
Each dataset item in Langfuse should have:
| Field | Description | Example |
|---|---|---|
input |
Classifier input (dict or string) | {"message": "How does pricing work?", "history": [...]} |
expected_output |
Expected classification result | {"intent": "LEARN"} |
metadata |
Optional context | {"source": "production", "site_name": "example"} |
Adding Traces to Datasets¶
To expand test coverage, add production traces to Langfuse datasets:
Option 1: Langfuse UI
- Go to Traces in Langfuse
- Find a trace with interesting/edge-case behavior
- Click Add to Dataset → select target dataset
- Fill in the
expected_output(ground truth label)
Option 2: Langfuse API
from langfuse import Langfuse
langfuse = Langfuse()
# Add item to existing dataset
langfuse.create_dataset_item(
dataset_name="intent-classifier",
input={"message": "Can you help me debug?", "history": []},
expected_output={"intent": "SUPPORT"},
metadata={"source": "manual", "notes": "Edge case for support detection"}
)
Environment Configuration¶
The eval command automatically configures:
LANGFUSE_ENABLED=true- Enables Langfuse for real prompt fetchingIX_ENVIRONMENT=test- Uses test environment (overridden todevelopmentfor credentials)
Test Markers¶
@pytest.mark.evaluation # Marks as evaluation test
@pytest.mark.llm_integration # Requires real LLM API calls
Running just eval all filters: -m "evaluation and llm_integration"
Results in Langfuse¶
After running evaluations, results appear in Langfuse:
| Score | Description |
|---|---|
correct |
Per-item: 1.0 if prediction matches expected, 0.0 otherwise |
confidence |
Per-item: Model confidence score (if available) |
macro_f1 |
Aggregate: Macro-averaged F1 score across all classes |
weighted_f1 |
Aggregate: Weighted F1 score |
accuracy |
Aggregate: Overall accuracy |
passed |
Aggregate: 1.0 if F1 >= threshold, 0.0 otherwise |
Quality Thresholds¶
Default thresholds (configurable in conftest.py):
| Metric | Threshold | Description |
|---|---|---|
| Macro F1 | 0.80 | Overall classification quality |
| Min Class F1 | 0.60 | No single class below this |
| Skill Recall | 0.90 | Multi-label skill coverage |
| Answer Accuracy | 0.70 | E2E response quality |